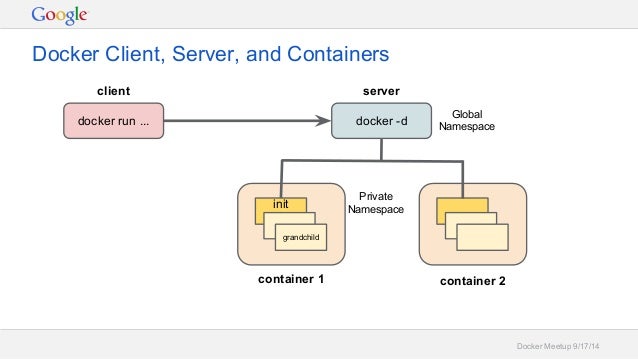
이전 kafka-spark streaming 을 사용하여 인기검색어에 대한 로그를 수집하려고 하였지만, 마땅히 테스트 할 서버가 없어서 우선은 logstash를 사용해서 바로 로그를 elasticsearch에 저장하기로 했다.그래서 기존에 kafka 카테고리에 연재를 하였는데 elasticsearch로 옮기게 되었다. 이전의 글들은 kafka 카테고리에 있습니다.
로그 저장 방법 변경
컴퓨터의 리소스부족으로 kafka-sparkstreaming을 사용하지 않고 logstash를 사용해서 바로 elasticsearch로 변경하기로 했다.ㅠㅠ 다음에 돈 많이 모아서 aws 서버하나 구성해야겠네..요...
할일 : 기존에는 search: 검색단어 에서 search: 검색단어 timestamp: 201910293847 로 변경 하기
grok filter를 사용해서 로그에서 searchword와 timestamp를 추가하기로 했다.
Apache 로그는 아래와 같다.
timestamp는 apache 로그 앞에 있어서 바로 사용하면 되겠다고 생각했다.
2019-10-05 14:13:19,069[http-nio-8080-exec-28]INFO c.k.k.c.HomeKDYController - 가위 Sat Oct 05 14:13:19 KST 2019그럼 파일을 logstash 를 사용해서 각 필드에 넣기 위해서. Grok 필터를 사용하기로 함.
grok 필터에 대해 알아보는데 스터디 시간(1시간)동안 시간을 소요한것같은데
이제서야 해답을 찾았다.
우선 grok 필터는 다음과 같이 설정 하면될 것 같다.
%{TIMESTAMP_ISO8601:timestamp},%{NUMBER:num}\[%{DATA:httpio}\]%{LOGLEVEL:log-level} %{DATA:class} \- (?<searchWd>[a-힣].)로그의 구성을 보면 timestamp,number,[httpio]loglevel class - searchword time 으로 동일했다.
이것을 각각에 맞게 다 작성해주고, searchWd만 개별로 customizing 해서 만들어줬다.
그럼 결과는 아래로 나온다. 이제 logstash의 conf에 추가를 해주면될것같다.
{
"timestamp": [
[
"2019-10-05 14:13:19"
]
],
"YEAR": [
[
"2019"
]
],
"MONTHNUM": [
[
"10"
]
],
"MONTHDAY": [
[
"05"
]
],
"HOUR": [
[
"14",
null
]
],
"MINUTE": [
[
"13",
null
]
],
"SECOND": [
[
"19"
]
],
"ISO8601_TIMEZONE": [
[
null
]
],
"num": [
[
"069"
]
],
"BASE10NUM": [
[
"069"
]
],
"httpio": [
[
"http-nio-8080-exec-28"
]
],
"log": [
[
"INFO"
]
],
"class": [
[
"c.k.k.c.HomeKDYController"
]
],
"searchWd": [
[
"가위"
]
]
}Log stash 내부 grok 필터
filter {
grok {
match => {"message" => "%{TIMESTAMP_ISO8601:timestamp},%{NUMBER:num}\[%{DATA:httpio}\]%{LOGLEVEL:log-level} %{DATA:class} \- (?<searchWd>[a-힣].)"}
}
}'BackEnd > ElasticSearch' 카테고리의 다른 글
| 내주변 주차장찾기 (2) (0) | 2019.12.01 |
|---|---|
| 내주변 주차장 검색 (1) (0) | 2019.12.01 |
| Excel 파일을 Spark-Elasticsearch 를 활용해서 데이터 저장하기 (0) | 2019.08.09 |
| Elasticsearch 모니터링 툴 설치 (0) | 2019.07.30 |
| 사전 만들기 프로젝트(3)-전처리된 데이터를 삽입해보자 (0) | 2019.06.29 |